Parámetros estadísticos
De Wikipedia
| Enlaces internos | Para repasar | Enlaces externos |
| Indice | WIRIS Geogebra Calculadora |
Tabla de contenidos |
Parámetros estadísticos
Después de haber representado los datos gráficamente, ahora llega el momento de hacer un estudio de los mismos. Existen una serie de datos que llamaremos parámetros estadísticos que nos sirven para representar a toda la población o que nos dan a información útil sobre la misma.
Parámetros estadísticos: Son datos que resumen el estudio realizado en la población. Pueden ser de dos tipos:
- Parámetros de centralización. Son datos que representan de forma global a toda la población. Entre ellos tenemos la media aritmética, la moda y la mediana.
- Parámetros de dispersión. Son datos que informan de la concentración o dispersión de los datos respecto de los parámetros de centralización. Entre ellos están el recorrido, la desviación media, la varianza y la desviación típica.
Parámetros de centralización
Moda
- Se define la moda como el valor de la variable que más se repite, es el decir, aquél que tiene mayor frecuencia absoluta. Se representa por Mo.
- Si hay dos o varias puntuaciones con la misma frecuencia máxima, la distribución es bimodal o multimodal, es decir, tiene varias modas.
Actividades en la que podrás aprender a calcular la moda de una distribución estadística.
Actividades en la que podrás aprender a calcular la moda de una distribución estadística.
Ejemplos con los que podrás aprender a calcular la moda de una distribución estadística.
Calcula en tu cuaderno la moda para el ejemplo número de hermanos: 2, 3, 2, 3, 3, 3, 3, 4, 2, 2, 2. Una vez que la tengas en tu cuaderno, calcúlala con la escena y compara los resultados.
Actividades:
a) Modifica las frecuencias y observa como puede variar el valor de la moda.
b) ¿Puede una distribución estadística tener más de una moda? ¿Pueden ser todos los valores de la variable?
Ejercicios con los que podrás comprobar lo aprendido sobre el cálculo de la moda de una distribución estadística.
Ejercicios de autoevaluación sobre el cálculo de la moda.
Cálculo de la moda con datos agrupados en intervalos
Llamemos intervalo modal al que tiene mayor frecuencia absoluta y consideremos dos casos:
- Si todos los intervalos tienen la misma amplitud, entonces la moda viene dada por la siguiente fórmula:
|
|
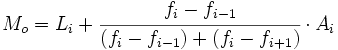
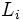 : Extremo inferior del intervalo modal :
: Extremo inferior del intervalo modal :
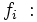 Frecuencia absoluta del intervalo modal.
Frecuencia absoluta del intervalo modal.
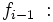 Frecuencia absoluta del intervalo anterior al modal.
Frecuencia absoluta del intervalo anterior al modal.
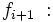 Frecuencia absoluta del intervalo posterior al modal.
Frecuencia absoluta del intervalo posterior al modal.
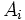 : Amplitud de los intervalos.
: Amplitud de los intervalos.
- Si todos los intervalos no tienen la misma amplitud, entonces la moda viene dada por la siguiente fórmula:
|
|
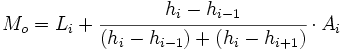
donde 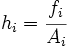 son las alturas de cada intervalo.
son las alturas de cada intervalo.
Moda correspondiente a una muestra:
- Definición.
- Ejemplos.
Cálculo de la moda para datos sin agrupar.
Cálculo de la moda para datos agrupados con o sin intervalos.
La moda. Ejemplos.
Ejercicios resueltos sobre el cálculo de la moda.
Media aritmética
Se define la media aritmética como la suma de todos los datos dividida por el número de datos. Se representa por 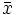 .
.
Cálculo de la media aritmética
- Para datos no agrupados, la media se calcula como sigue:
= 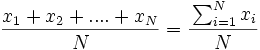
- donde
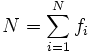 es el número total de datos observados.
es el número total de datos observados.
- Para el caso de datos agrupados puntualmente podemos simplificar el cálculo de la media aritmética con la fórmula:
= 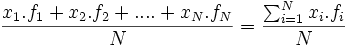
- Para el caso de datos agrupados por intervalos, el cálculo se hace de la misma forma pero utilizando como
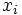 las marcas de clase, que son los valores centrales de cada intervalo (media aritmética de los extremos de cada intervalo).
las marcas de clase, que son los valores centrales de cada intervalo (media aritmética de los extremos de cada intervalo).
Media aritmética correspondiente a una muestra con datos agrupados o no agrupados.
Cálculo de la media para datos no agrupados.
Cálculo de la media para datos agrupados con o sin intervalos.
Actividades en la que podrás aprender a calcular la media aritmética de una distribución estadística.
Ejemplos de cálculo de medias aritméticas de un conjunto de datos no agrupados.
Calcula en tu cuaderno la media para el ejemplo número de hermanos: 2, 3, 2, 3, 3, 3, 3, 4, 2, 2, 2. Una vez que la tengas en tu cuaderno, calcúlala con la escena y compara los resultados.
Actividades:
- Modifica las frecuencias y observa como puede variar el valor de la media.
- ¿Cuál es el menor valor que puede tomar la media? Justifica la respuesta.
- ¿Cuál es el mayor valor que puede tomar la media? Justifica la respuesta.
Ejemplos de cálculo de medias de un conjunto de muchos datos agrupados o no por intervalos.
Calcula en tu cuaderno la media para el ejemplo de las estaturas: 1.59, 1.75, 1.71, 1.85, 1.64, 1.62, 1.66, 1.60, 1.63, 1.76, 1.66, agrupando los datos en intervalos. Una vez que lo tengas en tu cuaderno, calcúlala con la escena y compara los resultados.
Actividades:
- Modifica las frecuencias y observa como puede variar el valor de la media.
- ¿Cuál es el menor valor que puede tomar la media? Justifica la respuesta.
- ¿Cuál es el mayor valor que puede tomar la media? Justifica la respuesta.
- En este caso, se ha calculado la media utilizando intervalos, pero como tenemos pocos valores de la variable, calcúlala ahora utilizando la definición, es decir, suma todos las estaturas y divide el resultado por el número de alumnos y alumnas que hay. ¿Coincide el resultado? ¿Por qué?
Actividades para que practiques el cálculo de medias aritméticas de un conjunto de datos no agrupados.
Actividades para que practiques el cálculo de medias de un conjunto de muchos datos agrupados o no por intervalos.
Ejercicios de autoevaluación sobre la media aritmética.
La media aritmética. Ejemplos.
Ejercicios resueltos sobre la media aritmética.
Mediana
Si ordenamos todos los valores de la variable de menor a mayor, se define la mediana como el valor de la variable que está en el centro. Se representa por Me.
Cálculo de la mediana
Para calcular la mediana es necesario que los datos estén ordenados de menor a mayor. Se pueden dar los siguientes casos:
- Datos no agrupados o agrupados puntualmente: Si hay un número impar de datos observados, habrá un sólo valor central, mientras que si hay un número par de datos habrá que hallar la media de los dos valores centrales. En el caso de datos agrupados puntualmente deberemos guiarnos con las frecuencias acumuladas.
- Datos agrupados por intervalos: La mediana se encuentra en el intervalo donde la frecuencia acumulada llega hasta la mitad de la suma de las frecuencias absolutas. Es decir tenemos que buscar el intervalo en el que se encuentre
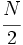 . Luego calculamos la mediana según la siguiente fórmula:
. Luego calculamos la mediana según la siguiente fórmula:
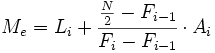
- donde:
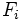 es la frecuencia acumulada del intervalo donde se encuentra la mediana y
es la frecuencia acumulada del intervalo donde se encuentra la mediana y 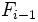 la frecuencia acumulada del intervalo anterior. Se cumple que
la frecuencia acumulada del intervalo anterior. Se cumple que 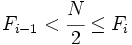 .
.
- es el límite inferior del intervalo donde se halla la mediana.
- es la amplitud del intervalo donde se halla la mediana.
Mediana correspondiente a una muestra:
- Definición.
- Ejemplos.
Cálculo de la mediana para datos no agrupados. Ejemplos.
Cálculo de la mediana para datos no agrupados. Ejemplos.
Cálculo de la mediana para datos agrupados sin intervalos. Ejemplos.
Cálculo de la mediana para datos agrupados en intervalos. Ejemplos.
Datos no agrupados:
Ejemplos con los que podrás aprender a calcular la mediana de una distribución estadística con los datos no agrupados.
Ejercicios con los que podrás comprobar lo aprendido sobre el cálculo de la mediana de una distribución estadística.
Ejercicios de autoevaluación sobre la mediana.
Datos agrupados puntualmente:
Ejemplos con los que podrás aprender a calcular la mediana de una distribución estadística con muchos datos en tabla de frecuencias.
Calcula en tu cuaderno la mediana para el ejemplo número de hermanos: 2, 3, 2, 3, 3, 3, 3, 4, 2, 2, 2. Una vez que la tengas en tu cuaderno, calcúlala con la escena y compara los resultados.
Actividades:
- Modifica las frecuencias y observa como puede variar el valor de la mediana.
- ¿Cuál es el valor menor que puede tomar? ¿Y el mayor?
Ejercicios con los que podrás comprobar lo aprendido sobre el cálculo de la mediana de una distribución estadística con muchos datos en tabla de frecuencias.
Datos agrupados puntualmente o por intervalos:
Actividades en la que podrás aprender a calcular la mediana y los cuartiles primero y tercero de una distribución estadística discreta (con datos agrupados puntualmente) o continua (datos agrupados por intervalos).
La mediana. Ejemplos.
Ejercicios resueltos sobre la mediana.
Actividades
Cálculo de la moda y la media para datos agrupados con o sin intervalos.
Cálculo de la media, mediana y moda para datos no agrupados.
Cálculo de la media, mediana y moda para datos agrupados en intervalos.
Parámetros de centralización.
Media aritmética, mediana y moda correspondiente a una muestra de 30 estudiantes en los que se observó el número de horas que pelan la pava diariamente.
Media aritmética, mediana y moda correspondiente a una muestra de 30 estudiantes en los que se observó el número de horas que estudian diariamente.
Parámetros de posición
Los parámetros de posición dividen un conjunto de datos ordenados en grupos con el mismo número de individuos. Hay tres tipos: cuartiles, deciles y percentiles.
Cuartiles
Los cuartiles son los valores de la variable que dividen la serie ordenada de datos en cuatro partes iguales.
- Los cuartiles son tres: Q1, Q2 y Q3, que delimitan al 25%, al 50% y al 75% de los datos, respectivamente.
- Q2 coincide con la mediana.
- La diferencia Q3 - Q1 se llama recorrido intercuartílico.
Cálculo de los cuartiles
Para calcular los cuartiles es necesario que los N datos estén ordenados de menor a mayor.
Procederemos como hacíamos con la mediana, pero ahora buscaremos el lugar que ocupa cada cuartil mediante la expresión
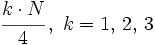
- en lugar del valor que usábamos para la mediana,
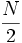 . (Fíjate que para k=2 se obtiene precisamente dicho valor, ya que Q2 es la mediana)
. (Fíjate que para k=2 se obtiene precisamente dicho valor, ya que Q2 es la mediana)
- Para el caso de datos no agrupados o agrupados puntualmente, el valor
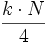 se redondea al siguiente número entero, y el dato ocupe dicho lugar será el cuartil.
se redondea al siguiente número entero, y el dato ocupe dicho lugar será el cuartil.
- Para el caso de datos agrupados en intervalos, la fórmula queda como sigue:
- Para el caso de datos no agrupados o agrupados puntualmente, el valor
|
|
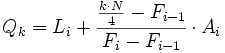
- donde:
- es la frecuencia acumulada del intervalo donde se encuentra el cuartil y la frecuencia acumulada del intervalo anterior. Se cumple que
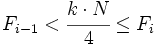 .
.
- es el límite inferior del intervalo donde se halla el cuartil.
- es la amplitud del intervalo donde se halla el cuartil.
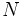 es el número de datos.
es el número de datos.
Actividades en la que podrás aprender a calcular los cuartiles de una distribución estadística.
Cuartiles. Ejemplos.
Ejercicios resueltos sobre cuartiles.
Deciles
Los deciles son los valores de la variable que dividen la serie ordenada de datos en diez partes iguales.
- Los deciles son 9: D1, D2 ... , D9, que delimitan al 10%, al 20%, ..., 90% de los datos, respectivamente.
- D5 coincide con la mediana.
Cálculo de los deciles
Para calcular los deciles es necesario que los N datos estén ordenados de menor a mayor.
Procederemos como antes, pero buscaremos el lugar que ocupa cada decil mediante la expresión
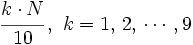
- Para el caso de datos no agrupados o agrupados puntualmente, el valor
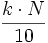 se redondea al siguiente número entero, y el dato que ocupe dicho lugar será el decil.
se redondea al siguiente número entero, y el dato que ocupe dicho lugar será el decil.
- Para el caso de datos agrupados en intervalos, la fórmula queda como sigue:
- Para el caso de datos no agrupados o agrupados puntualmente, el valor
|
|
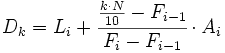
- donde:
- es la frecuencia acumulada del intervalo donde se encuentra el decil y la frecuencia acumulada del intervalo anterior. Se cumple que
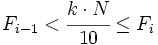 .
.
- es el límite inferior del intervalo donde se halla el decil.
- es la amplitud del intervalo donde se halla el decil.
- es el número de datos.
Deciles. Ejemplos.
Ejercicios resueltos sobre deciles.
Percentiles
Los percentiles son los valores de la variable que dividen la serie ordenada de datos en cien partes iguales.
- Los percentiles son 99: P1, P2 ... , P99, que delimitan al 1%, al 2%, ... , 99% de los datos, respectivamente.
- P50 coincide con la mediana.
Cálculo de los percentiles
Para calcular los percentiles es necesario que los N datos estén ordenados de menor a mayor.
Procederemos como antes, pero buscaremos el lugar que ocupa cada percentil mediante la expresión
|
|
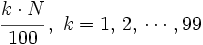
- Para el caso de datos no agrupados o agrupados puntualmente, el valor
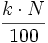 se redondea al siguiente número entero, y el dato que ocupe dicho lugar será el percentil.
se redondea al siguiente número entero, y el dato que ocupe dicho lugar será el percentil.
- Para el caso de datos agrupados en intervalos, la fórmula queda como sigue:
- Para el caso de datos no agrupados o agrupados puntualmente, el valor
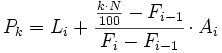
- donde:
- es la frecuencia acumulada del intervalo donde se encuentra el percentil y la frecuencia acumulada del intervalo anterior. Se cumple que
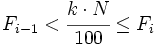 .
.
- es el límite inferior del intervalo donde se halla el percentil.
- es la amplitud del intervalo donde se halla el percentil.
- es el número de datos.
Percentiles. Ejemplos.
Ejercicios resueltos sobre percentiles.
En esta página web de "Portal Educativo" podrás encontrar ejemplos de cómo se calculan los parámetros de posición.
Cálculo de los cuartiles de una distribución con datos no agrupados.
Cálculo de los cuartiles de una distribución con datos no agrupados.
Cálculo de los deciles de una distribución con datos no agrupados.
Cálculo de los cuartiles de una distribución con datos agrupados puntualmente.
Cálculo de los cuartiles, deciles y percentiles de una distribución con datos agrupados en intervalos.
Cálculo de los cuartiles, deciles y percentiles de una distribución con datos agrupados en intervalos.
Cálculo de los cuartiles y del recorrido intercuartílico de una distribución con datos agrupados en intervalos.
Diagrama de caja y bigotes
En esta página web de "Estadística para todos" podrás encontrar ejemplos de diagramas de cajas y bigotes. Podrás aprender a construirlos y a utilizarlos para comparar distintas distribuciones. Comparar representaciones de datos. |  |
Parámetros de dispersión
Rango o recorrido
Se define el rango o recorrido como la diferencia entre el mayor y el menor de los valores de la variable. Se representa por R.
Rango o recorrido. Ejemplos.
Rango o recorrido. Ejemplos.
Ejemplos con los que podrás aprender a calcular el rango de una distribución estadística.
Actividades para comprobar lo que has aprendido sobre el cálculo del rango de una distribución estadística.
Desviación media
- La diferencia entre cada dato y la media aritmética del grupo se llaman desviaciones respecto a la media.
- Desviación media de un conjunto de datos es la media aritmética de los valores absolutos de las desviaciones respecto a la media. Nos indica el grado de dispersón (alejamiento) de los datos respecto a su media.
Desviación media. Ejemplos.
Desviación media con más datos. Ejemplos.
Desviaciones respecto a la media. Ejemplos.
Desviación media. Ejemplos.
Ejercicios de autoevaluación sobre el cálculo de la desviación media.
Ejercicios de autoevaluación sobre la desviación media.
Actividades en la que podrás aprender a calcular el rango y la deviación media de una distribución estadística.
Desviación media. Ejemplos.
Ejercicios resueltos sobre la desviación media.
Varianza
Se define la varianza como la media aritmética de los cuadrados de las desviaciones respecto de la media. Es decir:
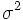 =
= 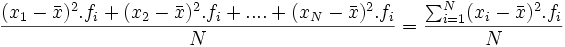
Se calcula más facilmente, con la siguiente fórmula equivalente:
= 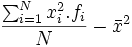
Si agrupamos los datos en intervalos, el cálculo se hace de la misma forma pero utilizando como las marcas de clase (valores centrales de cada intervalo que se calculan haciendo la media aritmética de los extremos de cada intervalo).
Varianza. Ejemplos.
Otra fórmula para la varianza.
Varianza. Ejemplos.
Ejercicios resueltos sobre la varianza.
Ejercicios de autoevaluación sobre la varianza.
Desviación típica
La varianza no viene expresada en las mismas unidades que los datos, ya que las desviaciones están elevadas al cuadrado. Para evitar esto se define la desviación típica.
Se define la desviación típica como la raíz cuadrada positiva de la varianza:

Cuanto más pequeña sea la desviación típica mayor será la concentración de datos alrededor de la media.
Desviación típica. Ejemplos.
Desviación típica. Ejemplos.
Ejercicios resueltos sobre la desviación típica.
Ejercicios de autoevaluación sobre la desviación típica.
Actividades y videotutoriales
Cálculo de la vararianza y de la desviación típica. Ejemplos.
Cálculo de la vararianza y de la desviación típica. Ejemplos.
Varianza y Desviación Estándar - Introducción y Ejercicio 1
Varianza y Desviación Estándar de Datos Agrupados de Variable Discreta
Varianza y Desviación Estándar para Datos Agrupados por Intervalos - Ejercicio 1
Actividades en la que podrás aprender a calcular la deviación típica y la varianza de una distribución estadística con datos agrupados puntualmente o por intervalos.
Ejemplos con los que podrás aprender a calcular la deviación típica y la varianza de una distribución estadística con datos agrupados puntualmente o por intervalos.
Calcula en tu cuaderno la varianza y desviación típica para el ejemplo número de hermanos: 2, 3, 2, 3, 3, 3, 3, 4, 2, 2, 2. Una vez que la tengas en tu cuaderno, calcúlala con la escena y compara los resultados.
Actividades:
- Modifica las frecuencias y observa como puede variar el valor de la desviación típica.
- ¿Cuál es el menor valor que puede tomar la desviación típica? Intenta construir un caso con desviación típica igual a 0. Justifica la respuesta.
- ¿Cuál es el mayor valor que puede tomar la desviación media? Justifica la respuesta.
- ¿Cómo hay que modificar las frecuencias para que aumente la desviación típica?¿Y para que disminuya?
Calcula en tu cuaderno el la varianza y desviación típica para el ejemplo del número de la estatura: 1.59, 1.75, 1.71, 1.85, 1.64, 1.62, 1.66, 1.60, 1.63, 1.76, 1.66, según hayas agrupados los datos en intervalos. Una vez que lo tengas en tu cuaderno, calcúlala con la escena y compara los resultados.
Actividades:
- Modifica las frecuencias y observa como puede variar el valor de la desviación típica.
- ¿Cuál es el menor valor que puede tomar la desviación típica? Intenta construir un caso con desviación típica igual a 0. Justifica la respuesta.
- ¿Cuál es el mayor valor que puede tomar la desviación media? Justifica la respuesta.
- ¿Cómo hay que modificar las frecuencias para que aumente la desviación típica?¿Y para que disminuya?
Ejercicios con los que podrás comprobar lo aprendido sobre el cálculo de la deviación típica y la varianza de una distribución estadística con datos agrupados puntualmente o por intervalos.
Parámetros de dispersión de una muestra:
- Recorrido.
- Varianza.
- Desviación típica.
Determina los parámetros de dispersión de una muestra de 100 estudiantes en los que se observó el número de hermanos.
Determina los parámetros de dispersión de una muestra de 50 piezas en las que se observó el peso de cada una.
Ejercicio sobre una distribución de notas de 20 alumnos. Deberás elaborar una tabla de frecuencias para calcular la media, la varianza, la desviación típica y la desviación media.
Ejercicio sobre una distribución de estaturas de 30 alumnos. Deberás elaborar una tabla de frecuencias para calcular la media, la varianza, la desviación típica y la desviación media.
Interpretación conjunta de la media y la desviación típica
De todas los parámetros estudiados, los más significativos son la media para las medidas de centralización y la desviación típica para las medidas de dispersión.
Vamos a hacer un estudio conjunto de ambas para entender mejor su significado.
La media aritmética es el centro de gravedad de la distribución estadística. Si nos imaginamos el diagrama de barras o el histograma de frecuencias apoyado en un punto del eje horizontal de forma que quedase en equilibrio, el valor de este punto en dicho eje sería el valor de la media.
Como ya hemos comentado, no es suficiente con un parámetro de centralización, es necesario un parámetro de dispersión que nos indique si los datos estudiados están más concentrados o más dispersos. Y este parámetro de dispersión va a ser la desviación típica. Lógicamente si los datos están más concentrados la desviación típica será menor, y si los datos están más dispersos la desviación típica será mayor.
Calcula en tu cuaderno la media y la desviación típica para la siguiente distribución del número de hermanos:
Comprueba los resultados obtenidos en la siguiente escena.
Actividades:
Modifica los valores de las frecuencias, y si quieres introduce más valores de la variable, hasta que el número de datos sea, por ejemplo, N=100. Construye ejemplos con las siguientes características:
- Dale a todas las frecuencias el mismo valor (el que quieras). ¿Cuánto vale la media? ¿Es lógico este resultado? ¿Cuánto vale la desviación típica?
- Ve disminuyendo en varios pasos las frecuencias de los valores centrales y aumentando por igual las frecuencias de los valores extremos, sin que varíe la media ni el número de datos. ¿Qué ocurre con la desviación típica? ¿Por qué sucede esto?
- Realiza ahora el procedimiento inverso, ve aumentando en varios pasos las frecuencias de los valores centrales y disminuyendo por igual las frecuencias de los valores extremos, sin que varíe la media ni el número de datos. ¿Qué ocurre con la desviación típica? ¿Por qué sucede esto?
- ¿Cómo será una variable estadística con desviación típica igual a 0? ¿Compruébalo en la escena?
Coeficiente de variación
Si hemos realizado un estudio estadístico en dos poblaciones diferentes, y queremos comparar resultados, no podemos acudir a la desviación típica para ver la mayor o menor homogeneidad de los datos, sino a otro parámetro nuevo, llamado coeficiente de variación.
El coeficiente de variación se define como el cociente entre la desviación típica y la media.
|
|
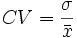
El coeficiente de variación se suele expresar en forma de porcentaje:
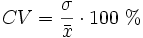
A una mayor dispersión de los datos le corresponderá un valor del coeficiente de variación mayor.
En una exposición de ganado estudiamos un conjunto de vacas con una media de 500 kilos y una desviación típica de 50 kilos. Y observamos también un conjunto de perros con una media de 40 kilos y una desviación típica de 10 kilos. ¿Qué grupo de animales es más homogéneo?
Solución:
Un razonamiento falso sería decir que el conjunto de perros es más homogéneo porque su desviación típica es más pequeña, ya que si calculamos el coeficiente de variación para ambos:
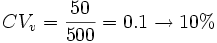 ;
; 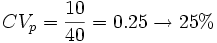
Por tanto, es más disperso el conjunto de los perros y más homogéneo el de las vacas.
Coeficiente de variación. Ejemplos.
Actividades en la que podrás aprender a calcular el coeficiente de variación de una distribución estadística.
Coeficiente de variación. Ejemplos.
Ejercicios y videotutoriales
Tutorial que explica, por medio de un sencillo ejercicio, los parámetros de dispersión: rango, desviación media, desviación típica o estándar y el coeficiente de variación.
Tutorial que explica los parámetros de centralización (moda, mediana, media) y de dispersión (rango, desviación media, desviación típica, coeficiente de variación), mediante un sencillo ejercicio de los personajes de los Simpson. En este ejercicio aparecen pocos en la muestra por lo que se utiliza la definición de cada uno de los parámetros para su cálculo sin necesidad de recurrir a una tabla de frecuencias ni a complejas fórmulas.
Ejercicio de cálculo de los parámetros de centralización y dispersión con datos discretos.
Ejercicio de cálculo de los parámetros de centralización con datos agrupados por intervalos
Ejercicio de cálculo de los parámetros de centralización y dispersión.
En esta página web de "Portal Educativo" podrás encontrar ejemplos de cómo se halla la media, la moda y la mediana para el caso de datos no agrupados o agrupados puntualmente.
En esta página web de "Portal Educativo" podrás encontrar ejemplos de cómo se halla la media, la moda y la mediana para el caso de datos no agrupados o agrupados puntualmente.
Ejercicio de autoevaluación sobre el cálculo de los parámetros de centralización y dispersión.

